Many students have a difficult time understanding standardization when starting out in learning statistics. Common questions often include:
- What does standardized mean?
- How do you standardize a score?
- Why should I give a damn?
The answers are fairly straightforward. Here’s a rundown for your statistical woes.
(Side note: I used R to put together the data for this tutorial. My code is shared at the end, if you’re interested in how I did everything)
What does standardized mean?
Put simply, to say that a score is standardized means that it has been converted from its original scale/metric into standard deviation units, more commonly known as a Z score. The Z score is arguably the most common type of standardized score, and its what we’ll work with here to make things easier for us.
Example: We want to know how well a student named Benny did on a test of spelling. This spelling test is a brand new measure; one that was made up by the education “expert” (whatever that means) at some school district. The test was administered to 500 students across the district. A local psychologist comes along and analyzes some of the student data and learns that Benny earned a score of 310 on this spelling test.
Cool… I guess. What exactly does this score tell us about Benny? Turns out, not much. Because our psychologist knows that this score of 310 isn’t super informative, she instead decides to report Benny’s spelling score as a standardized score. She informs us that Benny’s spelling test result is a Z score of -1.4.
Whether you realize it or not (yet) this way of conveying information about Benny’s score is actually much more informative than just knowing his raw score of 310. Here’s why.
You might have noticed that when the psychologist told us that Benny’s raw spelling score was 310, she didn’t tell us anything about the variability of the scores among all the test takers. We don’t know if everyone else also had scores that were about 310, or if lots of other people scored way higher than Benny or way lower than Benny. Should we be impressed by Benny? Should we be sad for him? Who knows. But the Z score gives us an answer., and it’s all because of how Z scores are calculated.
How do you standardize scores?
To calculate a Z score you need to know three things:
- The raw score we are trying to convert into a Z score
- The mean of the distribution that this raw score came from
- The standard deviation of that distribution
With these pieces of information in place, we’re good to go.
Just to be thorough, we can check the psychologist’s work by computing the Z score ourselves. The Z score formula is:

where:
- X = the raw score
- µ = the population mean
- σ = the population standard deviation
In practice, we pretty much never know what the population mean and population standard deviation actually are. That’s entirely the point of collecting data, after all – to try and estimate what those population values are (they’re commonly called population parameters). So instead we use what we can work with – the sample statistics.
The sample statistics are our best guesses as to what these population values really are. So we use those statistics to find Benny’s Z score. We simply find the sample mean (X̄) and the sample standard deviation (s), giving us a slightly different version of the Z score formula (it looks just like the previous formula):

The concept
Before we do the math, let’s take a step back. Most students see statistical formulas and copy them down, trying their best to memorize every component without really stopping to appreciate the idea behind a formula. I want to encourage you to do things differently. Take a moment to digest the concept behind what we’re actually doing here.
Recall above where I said:
“… to say that a score is standardized means that it has been converted from its original scale/metric into standard deviation units, more commonly known as a Z score.”
I remember because I just said it a couple of minutes ago. So let’s break that down a bit. We’re taking a score and translating it into standard deviation units. This simply means that when someone has a Z score of 1, that’s equal to 1 standard deviation. Z scores can be positive or negative, or equal to zero. The sign simply indicates whether their score is above(+) or below(-) the mean. So a Z score of -.5 means a person’s score is half a standard deviation below the mean, while a Z score of 2.2 means that a person’s score is 2.2 standard deviations above the mean. Furthermore a Z score of 0 indicates that there is no difference at all between a person’s score and the mean.
To understand where we are so far, you should understand what standard deviations are. If you don’t, take a moment to brush up on that concept. The brief explanation is that the standard deviation is the standard size of the difference between a population mean and any particular score that you plucked randomly from that population. (Keep in mind this is not the same as the mean deviation [which is just the average size of difference between a score and the mean], as the mean deviation has some bias built into it that minimizes the weight of larger values in your data, and makes it unsuitable for use in computing other statistics.)
So what are we doing here then? Again, we don’t know the population values so we have to use the sample statistics instead (because these statistics are our best guesses). In this case, the mean of the spelling test scores is equal to 450, and the standard deviation of the spelling test scores is equal to 100 (I know this because I created these data myself – see the code below to see how I did it).
So we can plug those values directly into the Z score formula to find a specific student’s Z score. To find Benny’s Z score, we can do it like this:
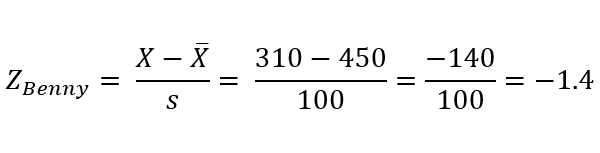
When finding Benny’s spelling test Z score, we’re basically running through two steps:
1) taking the difference between Benny’s score and the average spelling test score:
310 – 450 = -140
So we know that Benny’s score is 140 points below the average score. Which brings us to…
2) expressing that difference in standard deviation units by doing simple division:
-140 / 100 = -1.4
So now we can appreciate what Benny’s 310 actually says about his performance. And it’s… well, it’s not a great score. Benny could probably use some improvement.
We can also appreciate how low Benny’s score is by looking at the distribution of the data and finding Benny’s place among the other 500 students. We can see where his raw score falls below, relative to all the other raw scores:

And below, we see where his Z score falls among all the other Z scores. Note that the two distributions are more or less identical.

Why should we give a damn?
We should want to understand how to calculate and interpret Z scores. They help us out with scientific communication and collaboration. When we want to communicate our findings, the nature of our data can make things difficult for us sometimes. If we have variables that are measured in unusual or new ways, it can be tough to convey the significance (and I mean real significance, not statistical significance) of what you’ve found if you simply report raw scores.
The beauty of standardized scores such as the Z score is actually twofold. First, it’s a common enough metric that most people with statistical training can understand what it means, regardless of what discipline they work in. It doesn’t matter whether you’re an expert in education or an expert in mechanical engineering or an expert in ornithology, if you have basic stats training, you probably understand the meaning of a Z score of -1.4. Which brings us to the second benefit. Z scores naturally have information about variability built into them. When we tell another scientist that Benny’s spelling score is Z = -1.4, what we’re saying is that Benny’s score is nearly one and a half standard deviations below the average score. Knowing this, another scientist can quickly determine that not only is this score substantially low, it is actually lower than about 90% of the other 500 spelling test scores in the sample.
In Closing
You should realize that this sort of treatment applies only to normally distributed variables. It wouldn’t make sense to standardize a dichotomous variable (i.e., “yes/no” response). It also becomes problematic when we’re dealing with distributions that are very skewed or multi-modal (having two or more peaks instead of one).
Also, keep in mind that converting to Z scores is just one form of standardization, though it’s arguably the most common form. Other very common versions of standardization include Cohen’s d (aka the standardized mean difference) and Pearson’s r (aka the correlation coefficient). All forms of standardization accomplish the same basic function however – taking relatively arbitrary or scale-dependent statistical information and translating it into a metric that everyone can understand, regardless of their disciplinary background.
Standardization is an essential part of your basic statistical toolkit, and one worth knowing well.
Sample Code:
The R code I used for this tutorial is below. Free to all. Copy and paste it into R and play around with it if you’d like:
#create random spelling test outcome data.
require(dplyr)
set.seed(20190317)
d1 <- rnorm(500,m=450,sd=100)
spelling <- data.frame(d1)
names(spelling) <- c("score")
spelling <- spelling %>%
mutate(mu=mean(score), s=sd(score), diff=score-mu, Z=diff/s)
#compute Benny's Z score for the plot.
benny <- (310-mean(d1))/sd(d1)
benny
#plot of the raw score distribution.
#note that the theme function is entirely optional, and is customized and should only be included if you have the extrafonts package and the Josefin Sans font on your computer.
require(ggplot2)
plot1 <- ggplot(spelling, aes(x = score)) +
geom_histogram(aes(fill = ..count..), binwidth=30) +
ggtitle("Distribution of Spelling Test Scores\ (N=500 Students)")+
scale_x_continuous(name = "Spelling Test Score") +
scale_y_continuous(name = "Frequency/Count") +
geom_vline(xintercept = 310, size = 1, colour = "#FF3721",
linetype = "dashed", alpha=.8)+
geom_text(data=spelling, mapping=aes(x=310, y=45, label="Benny's Score = 310"), size=3, angle=90, vjust=-0.5, hjust=.4) +
scale_fill_gradient("Count", low = "yellow", high = "darkorange")
# theme(text=element_text(family="Josefin Sans", color="darkred"),
# plot.title=element_text(hjust = 0.5, size=14),
# legend.position = "none")
plot1
#plot of the Z score distribution.
#note that the theme function is entirely optional, and is customized and should only be included if you have the extrafonts package and the Josefin Sans font on your computer.
require(ggplot2)
plot2 <- ggplot(spelling, aes(x = Z)) +
geom_histogram(aes(fill = ..count..), binwidth=.3) +
ggtitle("Distribution of Spelling Test (Z Scores) \ (N=500 Students)")+
scale_x_continuous(name = "Spelling Test Score (Z score)") +
scale_y_continuous(name = "Frequency/Count") +
geom_vline(xintercept = -1.40, size = 1, colour = "#FF3721",
linetype = "dashed", alpha=.8)+
geom_text(data=spelling, mapping=aes(x=-1.40, y=45, label="Benny's Z score = -1.40"), size=3, angle=90, vjust=-0.5, hjust=.4) +
scale_fill_gradient("Count", low = "yellow", high = "darkorange")
# theme(text=element_text(family="Josefin Sans", color="darkred"),
# plot.title=element_text(hjust = 0.5, size=14),
# legend.position = "none")
plot2
#find common percentiles
percentiles <- quantile(spelling$score, c(.05,.10,.20,.30))
percentiles

You must be logged in to post a comment.